[Web Scraping 기초] BeautifulSoup을 이용한 웹 스크래핑
1) BeautifulSoup으로 원하는 요소 추출하기
- 다음 사이트에 있는 책들의 이름 정보를 스크래핑 해보자
http://books.toscrape.com/catalogue/category/books/travel_2/index.html
Travel | Books to Scrape - Sandbox
£44.34 In stock
books.toscrape.com
- 해당 웹 페이지는 임의의 책 정보가 담긴 웹 사이트이다.
- 스크래핑을 하기 위해선 특정 웹 페이지 전체에 어디 있는지 알아야 한다

- 그러기 위해선 전체 HTML을 분석할 줄 알아야 하는데, 이것을 돕는 도구가 웹브라우저의 '개발자 도구' 이다
- 알고싶은 곳에 커서를 두고 우클릭 후 검사 를 누르면 된다.
- 개발자 도구를통해 요소를 확인하고 그 태그를 타게팅해서 스크래핑 하는 것을 '콘텐츠 기반 스크래핑'이고 한다
- 방식은 간단하나 대상 사이트의 구조가 바뀔 가능성이 크기 때문에 그렇게 좋은 선택지는 아니다
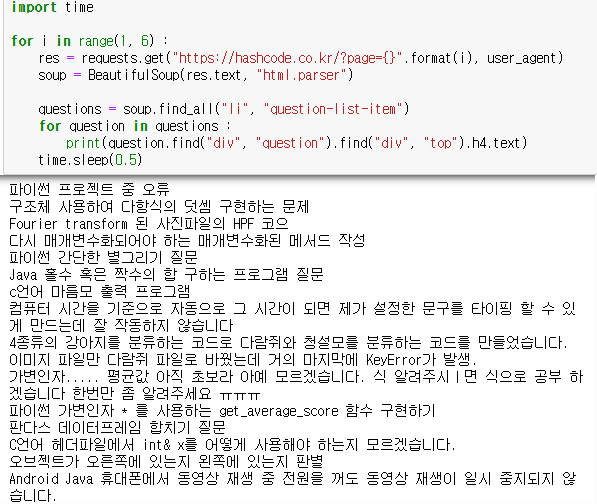
- 다음은 책 제목을 스크래핑하는 과정이다
① 스크래핑에 필요한 라이브러리 호출
import requests
from bs4 import BeautifulSoup② 예시 사이트에 get 요청 진행하고, 응답을 바탕으로 BeautifulSoup 객체 생성
res = requests.get("http://books.toscrape.com/catalogue/category/books/travel_2/index.html")
soup = BeautifulSoup(res.text, "html.parser")- 진행하기 전에 스크래핑 하고자 하는 사이트를 먼저 들어가 사이트와 관련한 이상유무를 먼저 확인하는 것이 좋다
③ <h3> 태그에 해당되는 요소 모두 찾기
- 책 제목은 h3 태그에 해당되는 요소이기 때문에 h3 태그에 해당되는 모든 요소를 찾는다

-
h3 = soup.find_all("h3")
h3
④ 제목 추출하기

- 스크래핑하고자 하는 책 제목은 a 태그의 콘텐츠이지만, a태그의 콘텐츠엔 책 제목이 일정 길이가 넘어가면 줄임말(...)
이 써져있는 것을 볼수있다
- 우리가 추출하고자 하는 진짜 제목은 a 태그의 속성(attributd)인 'title'에 있다는 것을 알 수 있다
- 태그 내 속성들은 key, value인 dict 형태로 저장되기 때문에 제목을 추출하기 위해선 다음과 같이 한다
for book in h3 :
print(book.a["title"]) # 위 반복문 보안
2) Locator로 원하는 요소 찾기
- 태그는 자신의 이름 뿐만 아니라 속성(attribute) 또한 가질 수 있다
- 이 중 'id'와 'class'는 대표적인 Locator로서, 특정 태그를 지칭하는 데 사용된다
※ id : "하나의" 고유 태그를 가리키는 라벨 / class : "여러(유사한)" 태그를 묶는 라벨
① Locator 없이 요소 가져오기


- Locator 없이 요소 찾게 되면 태그간 겹침으로 인해 원하는 요소를 가져오지 못하는 상황이 발생할 수 있다
② id를 활용하여 요소 가져오기
- id는 문서에서 unique한 별며이기 때문에 태그 단 하나를 쉽게 가져올 수 있다
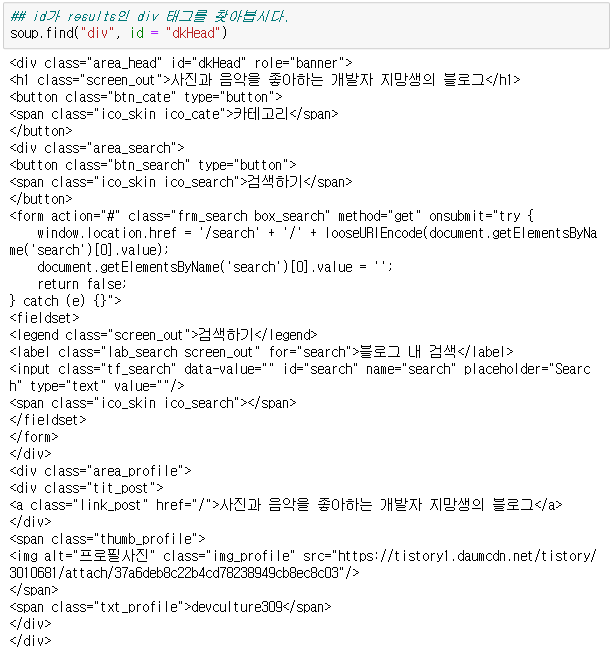
③ class를 이용해서 요소(들) 가죠오기
- class는 유사한 요소들을 구분짓는 별명이다.

3) 페이지네이션(Pagination)
- 많은 정보를 인덱스로 구분하는 기법이다
- 과도한 요청을 방지하기 위해 time.sleep 메소드를 활용하는 것이 좋다