
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 운영체제
- 데이터웨어하우스
- Django
- 데이터엔지니어링
- airflow
- 취준
- 기술면접
- 데이터베이스
- 개발
- 데브코스
- DataWarehouse
- 에어플로우
- 웹스크래핑
- AWS
- 부트캠프
- 관계형데이터베이스
- 웹자동화
- 웹크롤링
- CS
- 개념정리
- Amazon
- 알고리즘
- 프로그래머스
- 파이썬
- WEB
- Service
- 클라우드
- 자료구조
- SQL
- 데이터엔지니어
- Today
- Total
사진과 음악을 좋아하는 개발자 지망생의 블로그
[미니 프로젝트] 2017년 저 PER, 저 PBR 종목들의 5년 전 및 현재 시세 차이 비교 본문
프로그래머스 데이터 엔지니어링 코스를 수강하면서 2주차에 웹스크래핑에 대해 배워봤다.
웹스크래핑을 배우면서 미니프로젝트 하나를 해봐야겠다 생각했고, 토요일인 지금 미니 프로젝트를 진행하고자 했다.
무엇을 할까 고민을 하다가, 최근에 가지고 있던 주식에 수익이 나면서 주식에 대한 관심이 커졌다는 것을 알았다.
따라서!
주식과 관련된 미니프로젝트를 진행해보자 라는 생각이 떠올랐다.
주식을 처음 시작하면 항상 듣는 말이 있다.
"싸게 사서, 비싸게 팔아라"
이 말을 뜻을 열심히 찾아보면 바로 나오는 것이 있다
저 PER, 저 PBR
하지만, 요즘 주식 상황을 보면 코인 못지않은 광기와 혼돈 그 자체이기 때문에, 시장 경험이 적은 주린이에게 지금 당장 저 PER, 저 PBR 종목에 접근하는건 조금은 두려운 일이다. 하지만, 과거 저 PER, 저 PBR 종목들의 과거와 현재 시세 비교를 통해 저 종목들의 시세 성장을 증명할 수 있으면 저 PER, 저 PBR 종목 매수에 대한 두려움을 조금이나마 해소할 수 있지 않을까 하여 다음과 같은 주제를 잡고 미니 프로젝트를 진행하기로 하였다.
5년 전 저 PER, 저 PBR 종목의 5년 전 과 현재 간 시세 차이 비교
웹 사이트 선정
스크래핑하고자 하는 웹 사이트로 KRX | 정보데이터시스템 을 선택하였다
네이버 주식도 있지만 과거 PER, PBR을 한번에 조회하기 힘들면 스크래핑하는데도 불편하다 생각했기 때문에 때문에 과거 자료도 한번에 간편하게 볼 수 있는 한국거래소 정보데이터시스템을 활용하기로 하였다

저 PER, PBR 기준 및 시장구분
저 PER, PBR에 대한 기준은 정말 다양하지만, 약간 보수적인 관점으로 해서(?) 저 PER은 10, 저 PBR은 0.85 이하로 기준을 정하였다. 추가로, 종목은 KOSPI에 있는 종목으로 하였다.
데이터 추출과 저장(Extract and Load)
1) 종목 추출
저 PER, 저 PBR은 종목을 추출하는 과정은 다음과 같다
1. PER과 PBR을 조회할 수 있는 사이트로 들어간다
2. 시장구분은 kospi, 조회일자는 2023. 4. 21일 기준으로 5년 전인 2017. 4. 21.로 하고, 필터는 종목코드, 종목명,
PER, PBR로 하여 종목들을 조회한다
3. 조회된 종목을 PER과 PBR 기준으로 각각 오름차순 후 PER이 10 이하, PBR 0.85인 종목을 각각 따로 스크래핑한다
4. 연도별 시세를 조회할 수 있는 사이트 로 들어간다
5. 대상선택은 '개별종목', 기간을 '연도별', 2018로 설정하고, 종목코드를 검색하여 종목명을 넣은 후 조회한다
6. 조회된 시세에서 2018년 종가와 2023년 종가를 추출하여 변화율을 기록한다
7. 스크래핑한 종목 전체를 대상으로 5 ~ 6 번을 시행한다
8. 작업이 완료되면 종목코드가 겹치는 종목들은 따로 리스트를 생성하여 저장한다
2) 저장
- 저 PBR, 저 PER, 저 PBR/PER 리스트를 각각 CSV 파일로 저장한다
결과 확인

생각보다 많은 데이터가 나왔다.
중간에 사이트가 접근을 거부하는 경우도 나왔었지만 그래도 무사히 마무리 하였다
시각화를 하면서 종목들의 시세 성장률을 확인하는데 10배가 넘는 성장률 기록하는 종목들도 있었다.(e. g. 금양 2500%)
솔직히 성장률 100%도 정말 운이 좋다고 생각하기 때문에 성장률 500%까지 제한하여 자료들을 다시 가공하였다
최종 결과
1) 저 PER종목들의 5년 후 시세 성장률

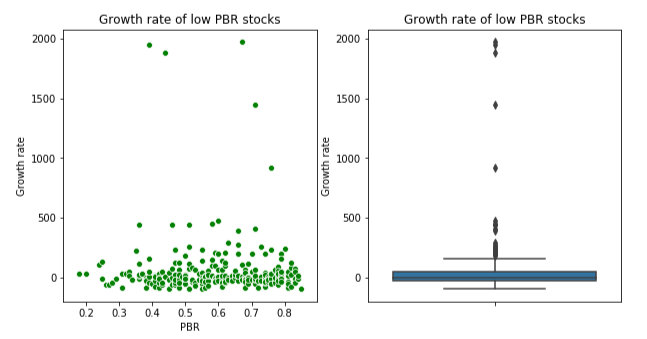
2) 저 PBR 종목들의 5년 후 시세 성장률
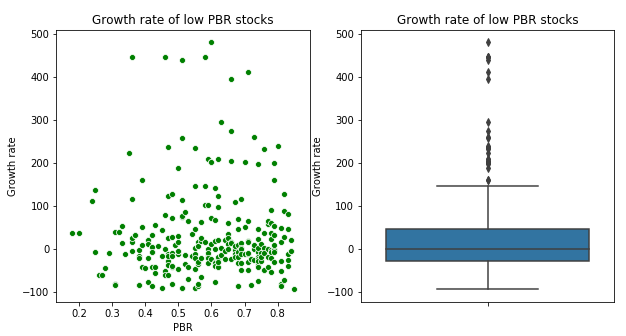
3) 저 PER & 저 PBR 종목들의 5년 후 시세 성장률

4) 저장된 자료

결론
- 저 PBR, 저 PER 종목들은 '평균적'으로 상승하는 경향이 있었다
- 하지만, 말도 안되는 성장을 종목들도 있었지만 상장폐지나 거래정지가 된 종목들도 있었다
- 또한, 전 범위를 고려하지 않았기 때문에, 이번 프로젝트에서 '저 PBR, 저 PER 종목들은 장기 투자를 하면 왠만하면
수익을 얻는다'나는 명제가 참이라고 증명하기엔 부족하다고 느꼈다
※ 따라서, 투자할 시 PBR, PER 뿐만 아니라 여러 방면으로 이리 따지고 저리 따져서 투자해야 한다.
미니프로젝트를 마치며
1. 신중하게 데이터를 추출하자
중간에 나의 명제를 증명하기 위한 데이터를 추출하는 소스를 짜면서 중간에 저 PBR, 저 PER 종목들 선정하는건 잘못됐다는 것을 깨달았다. 왜냐하면, 저 PBR, 저 PER의 종목들의 시세 성장률이 높다는 것을 증명하려면 다른 PER, PBR 종목들의 시세도 비교할 수 있어야 했기 때문이다.
즉, 나는 전 종목의 PER, PBR과 시세를 추출했어야 했다
이런 경험을 하면서, 데이터를 추출할 때, 내가 뽑아내고자 하는 데이터가 이것만으로 충분한건지,
만약 다른 사람이 A와 관련된 정보를 추출해서 저장해달라고 할 때 정말 A와 관련된 정보가 정확히 무엇이 있는지,
고려해야할 건 더 없는지 굉장히 신중하게 판단해야한다는 것을 느꼈다
2. 내가 보고 있는 HTML 소스가 영원할 거라 생각하지 말자
자동화 기능을 위한 소스를 짜던 중 자리를 비운지 4분 만에 분명 같은 소스인데 오류가 발생하는 경험 하였다.
왜그런지, 이것저것 분석하던 중, 태그 속성인 id 값이 변하는 것을 확인할 수 있었다.
이는 무분별한 웹스크래핑을 방지하고자(뇌피셜) 태그 속성인 id값을 수시로 변하도록 한 것 같았다.
다행히, 이것은 해당 요소의 class 값이 해당 페이지에서 유일하면서 변하지 않는 값임을 확인하고 class 값으로 해당 요소를 찾아 원하는 동작을 할 수 있도록 오류를 해결하였다.
이러한 경험을 통해, 내가 보고 있는 HTML 소스를 있는 그대로 믿지 말고, 내가 어떤 요소를 사용할 때 어떤 속성을 사용할 수 있는지, 그 속성은 사이트가 새로고침을 할때마다 변하는 속성은 아닌지 확인해 보고 사용해야한다는 것을 느꼈다. 또한, 단순히, 내가 잘 쓸수있다 생각되는 find_element 메소드, id 속성, XPATH만 맹신해서 쓰지말고, 내가 쓰고자 하는 요소에 접근 방법을 다양하게 떠올려야 한다는 것을 느꼈다
3. 더 빠르게 할 순 없을까
데이터를 추출하고 과정에서 시간이 너무 소요된다는 것을 느꼈다.
저 per 종목들의 시세를 조회할 때 걸리는 시간을 고려해 time.sleep 시간을 넉넉히 주다 보니, 데이터를 추출하는 시간이 증가하였다.
내가 만약 돈을 주고 데이터를 요청하는 의뢰자라면, 최대한 빨리 데이터를 받고 싶어할 꺼다. 하지만, 이런 속도로 데이터를 추출하면 다음 기회는 없을 것이다.
할 수 있는 한도 내에서, 최대한 '빠르고', '정확하게' 데이터를 추출하는 방법을 고민해봐야겠다